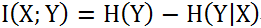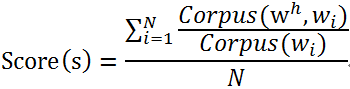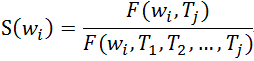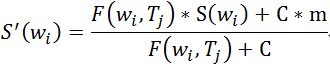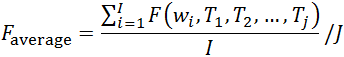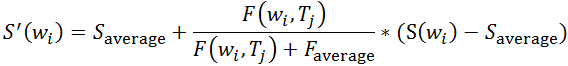1、从NLP中的3个任务说起
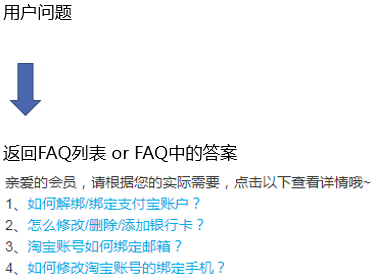
语义匹配(Semantic Matching)或者说语义相似度(Semantic Similarity)有许多应用场景:搜索引擎中的网页搜索,问答系统FAQ问答中的FAQ与用户query的匹配,feeds流中相似feeds的召回等等。
2013年发表的经典的DSSM模型为深度语义匹配问题提供了思路。DSSM解决的问题是利用搜索场景中query和网页点击数据,对文本语义相似度进行建模,从而对用户query召回相关网页。![参考文献[1]](/images/machine_reading_attention/figure1.png)
这篇文章用DNN将高维sparse文本特征(one-hot,特征长度为整个数据库的词典长度),实际上是lexical级别的,表达为低维dense语义特征,然后利用cosine距离来计算两个文本的相似度。
自然语言推理(Natural Language Inference),或文本蕴涵(Textual Entailment, TE),解决的问题是分析推理前提(premise)与推理假设(hypothesis)之间是否存在蕴含(entailment)、矛盾(contradiction)或者中立(neutral)关系。下图为斯坦福大学提出的大规模自然语言推理任务数据集SNLI论文中的神经网络分类结构。![参考文献[2]](/images/machine_reading_attention/figure2.png)
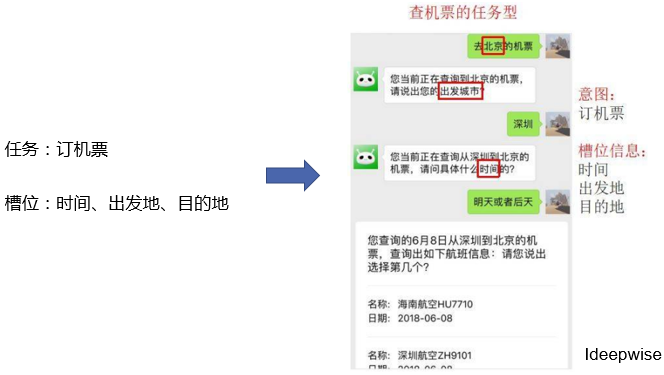
机器阅读理解(Machine Reading Comprehension) 主要包括多项选择(multiple choice questions)、完形填空(cloze style comprehension)、开放式问题(也叫短文本生成类问题;给出问题,从非结构化整理的文本中得到答案;具体又分为总结答案和答案来自原文两种类型)三种任务类型。下文提到的一些包含注意力机制的模型,主要是为解决开放式阅读理解问题。具体设定是输入问题,及给出的答案所在的文档段落,输出答案。下图是将神经网络引入阅读理解任务的三种结构:![参考文献[12]](/images/machine_reading_attention/figure3.png)
可以看出,解决这些任务问题的深度神经网络结构框架可以简单概括为: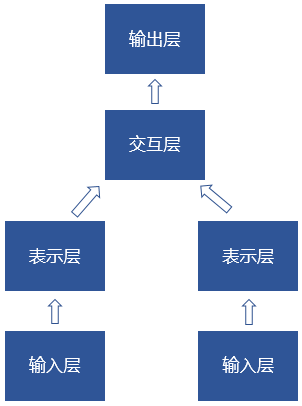
两路输入根据任务的不同可能是query与FAQ中的问题,前提与假设,或query与文档段落。表示层可以是预训练的embedding,DNN,RNN等各种设计。交互层也可以没有,由两路表示层的距离计算作为输出层。交互层可以是MLP,现在往往是各种类型的attention设计,网络层数各异,输出层根据不同的任务可以有不同的设计。
网络结构中,重点就是要做好表示和交互信息的表达了。语义匹配要建模两个句子的语义相似度,NLI要建模两个句子的推理信息,MRC要建模两个句子的问答关系,可见,交互信息层尤为重要,这里可以理解为是不同关系的matching。而注意力机制(attention mechanism,下文简称attention),是建模交互信息的重要方法。本文重点从阅读理解任务的角度,看看attention的一些不同设计。
2、sequence to sequence model
要说attention,不得不先提sequence to sequence model,从输入序列学习得到输出序列的一个general end-to-end的方法[4]。最早是在翻译任务中被提出应用。如下图所示,模型接受输入句子“ABC”,输出句子”WXYZ”。![参考文献[4]](/images/machine_reading_attention/figure5.png)
Encoder将输入句子编码成一个固定长度的向量,解码端根据这个向量及之前时刻的输出信息,得到下一时刻的输出。
在Encoder-Decoder的框架里,编码器接受输入序列$x=(x_{t},…,x_{T_{x}})$,编码得到向量c:
$h_{t}=f(x_{t},h_{t})$
$c=q( \{ h_{1},…,h_{T_{x}} \} )$
解码端,模型根据在context vector c,及previous输出词语,预测下一个时刻的输出。
$p(y)=\prod_{t=1}^{T}p(y_{t}|\{ y_{1},…,y_{t-1} \},c) $
3、注意力机制
注意力机制(attention mechanism)有两种类型,soft及hard。Hard attention利用
按概率进行采样的方法决定“注意”哪些信息单元(如某个神经元的值)或“不注意”哪些信息单元。Soft attention则给各个信息单元都赋予权重系数,“注意力”更平滑。
本文在这里只讨论soft attention。attention在Handwriting Synthesis任务中被首
次提出[5]。Handwriting Synthesis即根据给定的文本,生成手写体。
在这篇文章中,其实没有提到attention的概念,文章中提的是condition,利用a “soft window”来控制text string的高维表达的不同权重。
Bahdanau[6]则把这个思路优雅地用在了NLP的machine translation里。文章提出的网络结构不是把整个输入句子编码成一个固定长度的向量,而是把输入序列encode成一个向量序列。![参考文献[6]](/images/machine_reading_attention/figure7.png)
采用RNN结构,解码端的概率输出如下:
$p(y_{1},…,y_{i-1},\textbf{x})=g(y_{i-1},s_{i},c_{i})$
$s_{i}=f(s_{i-1},y_{i-1},c_{i})$
其中,context vector c由隐藏层向量h的带权加和得到:
$c_i=\sum_{j=1}^{T_{x}}{\alpha_{ij} h_{j}}$
其中,每个隐藏层向量h的权重α计算如下:
$\alpha_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_{x}} exp(e_{ik})}$
$e_{ij}=a(s_{i-1},h_{j})$
权重$\alpha_{ij}$表达从第j个输入序列隐藏层向量和第i-1个输出序列隐藏层向量来看,第j个输入序列隐藏层向量和第i个输出序列隐藏层向量的相关程度。宏观看来,即输入序列中第j个单词$x_{j}$对输出序列中第i个单词$y_{i}$的输出有多少影响。那么$c_{i}$就是输入序列中各个单词在输出第i个单词时的预期的影响程度系数(expected annotation)。a表示一个建模函数,在这里用a feed forward neural network实现。
4、attention的各种设计
4.1 attention over attention
![参考文献[8]](/images/machine_reading_attention/figure8.png)
这是哈工大的一篇论文[8],出发点是解决阅读理解中的完形填空问题。模型结构一目了然的。想用点乘的attention计算方式对document及query计算attention,然后计算column-wise及row-wise softmax,分别得到的query注意document,及document注意query的attention系数,然后再次利用点乘计算document及query的attention信息,此之谓attention over attention。
4.2 word-by-word matching
由match-lstm实现。match-LSTM最早提出是在文章[9]。其最初在Natural Language Inference(NLI)任务中被提出,用于获取假设(hypothesis)与前提(premise)的word-by-word matching,以对不同的词语给予合适的注意力权重。
传统的attention操作主要关注的是一个向量对另一个向量的“注意力”,文章指出在NLI问题中,这是利用a single vector representation of the premise,to match the entire hypothesis。
而这篇文章提出的模型整体的结构如下图所示:在传统的attention层上,设计了mLSTM层来建模matching,得到$h^{m}$。![参考文献[9]](/images/machine_reading_attention/figure9.png)
其中,s上标表示premise的信息,t上标表示hypothesis的信息。可见每一个时刻,hypothesis的词语对premise的注意力权重都有所调整。计算公式如下:
$a_{k}=\sum_{j=1}^{M} \alpha_{kj}h_{j}^{s}$
$\alpha_{kj}=\frac {exp(e_{kj})} {\sum_{j^{‘}} exp(e_{kj_{‘}})}$
$e_{kj}=w^{s}tanh(W^{s}h_{j}^{s} + W^{t}h_{k}^{t} + W^{m}h_{k-1}^{m} )$
其中$h_{k}^{m}$ 由match-lstm得到。
下面介绍一下match-lstm。经典LSTM利用一些gate vectors来控制模型中序列信息的passing,公式如下:
$i_{k}=\sigma(W^{i} x_{k}+V^{i} h_{k-1} + b^{i}) $
$f_{k}=\sigma(W^{f} x_{k}+V^{f} h_{k-1}+b^{f} )$
$o_{k}=\sigma(W^{o} x_{k}+V^{o} h_{k-1}+b^{o})$
$c_{k}=f_{k}\odot c_{k-1}+i_{k}\odot tanh(W^{c} x_{k}+V^{c} h_{k-1}+b^{c} )$
$h_{k}=o_{k}\odot tanh(c_{k})$
Match-lstm公式如下:
$i_{k}^{m}=\sigma (W^{mi} m_{k}+V^{mi} h_{k-1}^{m}+b^{mi} )$
$f_{k}^{m}=\sigma (W^{mf} m_{k} + V^{mf} h_{k-1}^{m}+b^{mf} )$
$o_{k}^{m}=\sigma (W^{mo} m_{k}+V^{mo} h_{k-1}^{m}+b^{mo})$
$c_{k}^{m}=f_{k}^{m}\odot c_{k-1}^{m} + i_{k}^{m}\odot tanh(W^{mc} m_{k}+V^{mc} h_{k-1}^{m}+b^{mc} )$
$h_{k}^{m}=o_{k}^{m}\odot tanh(c_{k}^{m})$
与典型LSTM的区别在于控制单元c:
$m_{k}=\left[ \begin{array}{c}
a_{k}\
h_{k}^{t}
\end{array}\right ] $ 融合了对于hypothesis中第k个词语的attention-weighted的premise信息,以及hypothesis中第k个词语本身的信息。这里利用了LSTM来match the premise with the hypothesis using the hidden states,实现word-by-word matching。
同一作者的文章[10]将match-lstm及pointer net用于阅读理解的生成式任务,主要针对SQuAD数据集。![参考文献[10]](/images/machine_reading_attention/figure10.png)
这是第一篇文章将end-to-end的神经网络模型引入开放式阅读理解问题。模型包括LSTM Preprocessing Layer, Match-LSTM layer, 以及Answer Pointer Layer。有了上面对match-lstm的解释,这个模型结构就一目了然了。其中Answer Pointer Layer输出层又包含The Sequence Model和The Boundary Model两种类型,前者生成答案文本,后者生成答案文本所在的起始和结束字符。实验表明,神经网络的Boundary模型能获得state-of-the-art的效果。后面的模型也基本采用这种答案预测的方式。
4.3 共同注意力机制(coattention)
模型的整体结构包括question和document的coattentive encoder,以及a dynamic pointing decoder预测答案片段的起始和结束位置。
![参考文献[11]](/images/machine_reading_attention/figure11.png)
![参考文献[11]](/images/machine_reading_attention/figure12.png) )
)
联合注意力机制,a coattention mechanism,使得模型同时注意question及document。
具体的模型结构分成以下几个部分:
1)Document and question encoder
利用LSTM对document及question进行编码,To allow for variation between the question encoding space and the document encoding space,在question encoding加a non-linear projection layer:
$Q=tanh(W^{(Q)}Q^{‘}+b^{(Q)} \in \mathbb{R}^{l \times (n+1)} $
其中$Q^{‘}$是LSTM对question编码,而Q是经过全连接层后的对question的编码。
2)Coattention encoder
首先计算包含文档(D)和问题(Q)关系的affinity matrix(相似度矩阵):
$L=D^{\top}Q \in \mathbb{R}^{(m+1)\times(n+1)}$
然后分别进行row-wise和column-wise的normalization,以得到文档对于每一个问题词的attention weights以及问题对每一个文档词的attention weights。
$A^{Q}=softmax(L) \in \mathbb{R}^{(m+1) \times (n+1)}$
$A^{D}=softmax(L^{\top}) \in \mathbb{R}^{(n+1) \times (m+1)}$
接着计算attention contexts,充分结合了document及query来计算交互的attention信息:
$C^{Q}=DA^{Q} \in \mathbb{R}^{l \times (n+1)}$
相似地计算:$QA^{D}$
然后是一个前述attention信息的总结计算:
$C^{D}=[Q;C^{Q}]A^{D} \in \mathbb{R}^{2l \times (m+1)}$
终于到了图中U向量的计算,作为coattention encoding的输出,后面decoder的输入。
$u_{t}=BiLSTM(u_{t-1},u_{t+1},[d_{t};c^{D}_{t}]) \in \mathbb{R}^{2l}$
这便是上图coattention encoder的计算过程。
3)Dynamic pointing decoder![文献[11]](/images/machine_reading_attention/figure13.png)
到了解码层,简单说来,这里其实是用了一个LSTM:
$h_{i}=LSTM_{dec}(h_{i-1},[u_{s_{i-1}} ;u_{e_{i-1}} ])$
其中,h表示LSTM的hidden state,s和e分别表示答案的初始和结束位置的estimate向量(下标i表示时刻),即我们需要的输出。s和e的计算是分开的, 其输出直接表达了答案的起始和结束位置的输出概率分布:
$s_{i}=\mathop{\arg\max}_{t} (\alpha {1},…,\alpha{m})$
$e_{i}=\mathop{\arg\max}_{t} (\beta {1},…,\beta{m})$
其中:
$\alpha {t} = HMN{start}(u_{t},h_{i},u_{s_{i-1}} ,u_{e_{i-1}})$
可见,s和e的计算过程需要双方的参与,同时也考虑LSTM的hidden state。而LSTM的hidden state的计算也需要s和e的信息。所以这个过程是迭代的,互相渗透的。用算法的话说,就是矩阵计算的过程中,hidden state的计算有s和e作为输入,s和e的计算有hidden state作为输入。
s和e的计算,文章提出了HMN网络,即Highway Maxout Network,基于Maxout Networks和High-way Networks的结合。网络结构如下图所示。![文献[11]](/images/machine_reading_attention/figure14.png)
具体计算方法如下: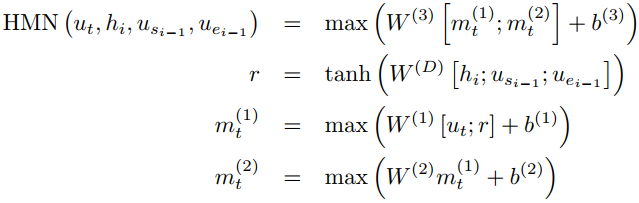
Maxout Networks出自2013年的文章[14]。Maxout的计算方法是对神经元用多套W参数进行计算,每一套参数的计算也可以看作是一层网络,输出结果是对各个位置的多层网络的输出结果取最大值。这里还利用High way的思路,输出值不止是取最大值,而是将多层网络的结果都参与计算。
4.4 双向attention
这里要提到的论文,是BIDAF。通俗地说,就是从passage的角度,对query的attention,以及从query的角度,对passage的attention。
这是华盛顿大学Allen Institute for Artificial Intelligence实验室提出来的一个有名的阅读理解end-to-end模型。这篇文章的模型是在以往工作的基础上,强调了多角度和query-aware的注意力机制(attention mechanism,下文简称attention)设计,从而使得注意力机制能够关注到更多不同的信息。
文章总结了之前的attention工作往往有以下特点:1)将context(上下文)summarizing(总结)成一个固定长度的向量,然后从中提取最相关的信息来回答问题;2)in the text domain,attention是temporally dynamic的。笔者理解,意思是人在阅读文本的时候,注意力思维(关注的点)是灵活的,可以结合过去、当前的文本,甚至会阅读了后面的内容后回过头来思考,这就整合了过去、现在、未来的不同时刻的文本信息。而现有的注意力机制模型的设计,当前时刻的注意力权重(attention weights)只是过去信息的注意力向量函数。3)这些attention函数往往是单向的,query“注意”上下文段落。
针对这些分析,文章提出一个多层模型,从不同的粒度(granularity)来表达上下文信息,并用一个双向的attention flow mechanism来得到query-aware的context表达(context也“注意”query了)。其一,注意力层不是将context paragraph总结成一个固定长度的向量,而是每个时刻都计算注意力信息,而且当前时刻和以前时刻的信息表达都可以在每个时刻的注意力信息计算过程中通过the subsequent modeling layer体现(flow),这就减少了信息丢失。另一方面,减少了attention信息的记忆,当前时刻的注意力机制的计算只会依赖query和当前时刻context paragraph的信息,不会直接依赖之前时刻注意力信息的计算结果。
文章认为这种简化让attention layer和modeling layer分工更明确了。它促使attention层集中关注query和context的attention信息,modeling 层集中关注query-aware context表达信息的相互作用。同时,每个时刻的attention信息可以不受之前时刻不准确的attention信息的干扰。这篇文章注意力机制的计算是双向的,包括query-to-context及context-to-query。![文献[13]](/images/machine_reading_attention/figure16.png)
模型具体为:
- Character Embedding Layer
- Word Embedding Layer
- Contextual Embedding Layer
- Attention Flow Layer
- Modeling Layer
- Output Layer
首先是character embedding及word embedding层,character embedding由卷积神经网络得到,word embedding利用了预训练的GloVe向量。
然后contextual embed layer利用LSTM对embedding不同时刻的信息进行建模,得到passage及query信息的表达。这也可以看作是从不同粒度(granularity)来建模对输入文本,包括query和passage,进行建模。
Attention flow layer主要对query和 passage的信息进行关联和聚合,获取交互信息。与以往的工作不同,attention flow layer不是将query和paragraph的信息整合成一个特征向量。在每个time step,previous layers的信息,也会在attention中有所体现。而且,attention的计算是双向的:从context看query ,及从query看context。具体的计算流程如下:
1)首先,计算一个共享的相似度矩阵:
$S_{tj}=\alpha(H_{:t},U_{:j})$
$S_{tj}$表示第t个paragraph word,及第j个query word的相似度。α是一个可训练的函数。
$\alpha(\textbf{h},\textbf{u})=w_{S}^{\top} [\textbf{h};\textbf{u};\textbf{h}∘\textbf{u}]$
;表示向量concate, ∘表示elementwise multiplication。
2)Context-to-query attention 表达对于每个paragraph中的词语,哪个query word相关性最大,即从context看query。$\alpha_{t}$表示对于第t个paragraph word,各query word的权重,由相似度矩阵$\textbf{S}$的第t个向量计算得到。
$\mathbf{\alpha}{t}=softmax(\textbf{S}{t})$
$\widetilde{\textbf{U}{:t}}=\sum{j} \mathbf{\alpha}{tj} \textbf{U}{:j} $
3)Query-to-context attention则表达对于每个query word,context words的权重分布,即从query看context。
$\textbf{b}=softmax(max_{col}(\textbf{S}))$
注意,这里先对相似度矩阵S按列求最大值。然后计算注意力context vector:
$\widetilde{\textbf{h}}=\sum_{t} \mathbf{b}{t} \textbf{H}{:t}$
然后会对$\mathbf{h}$向量复制T次,从而获得$\widetilde{\mathbf{H}}$,与$\widetilde{\mathbf{U}}$维度相同。每个context word看query,$\mathbf{S}$矩阵中每一列可以看作是一个context word与所有query words的信息,直接按列softmax就可以。笔者思考,而query看context words,阅读理解的输出不是sequence的输出,所以query应该作为一个整体来看每个context words的贡献,所以这里每个context word只保留了与query word相似度最高的相似度值。不过这个操作更是为了下面的计算。
综合以上结果,可以得到对于每个context word的query-aware表达。下面的公式即表示对于第t个context word,query words的注意力权重了。
$G_{:t}=\beta (\mathbf{H}{:t},\widetilde{\mathbf{U}{:t}},\widetilde{\mathbf{H}_{:t}})$
这里β是任意一个可训练的神经网络。
在contextual embedding layer,context words的交互信息与query word是相对独立的。所以接下来,Modeling layer利用一个双向LSTM来进一步获取context和query的交互信息。这层的输出就包含于整个paragraph和query相关的contextual信息了。
Output layer就可以根据任务进行设计了。这篇文章在短文本生成型和完型填空型的阅读理解数据上都有实验。对于squad数据集,模型通过输出答案文本的start及end位置实现。
4.5 self-matching
这里提到的也是一个经典的模型,微软亚洲研究院提出的RNET。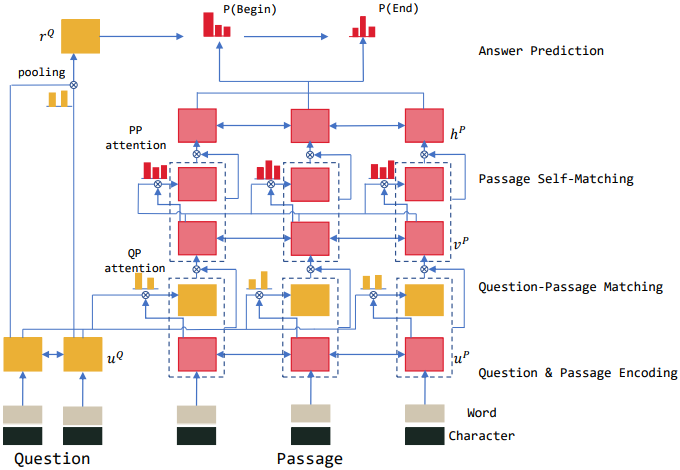
模型包括四个部分:
(1)question and passage encoder
question及passage的表达通过双向GRU分别构建。
(2)gated attention-based recurrent networks
通过门控注意力机制的循环神经网络,来match question及passage的信息。这里的
具体计算公式与match-lstm类似,对于上文match-lstm中提到的$m_{k}$,即这里的$[ u_{t}^{p},c_{t}]$,加上一个门控机制:
$g_{t}=sigmoid(W_{g}[ u_{t}^{P},c_{t} ])$
$[ u_{t}^{p},c_{t}]^{*} = g_{t} \odot [ u_{t}^{p},c_{t}]$
(3)self-matching attention
passage的信息对于推断答案来说非常重要。因此,文章提出直接matching question-aware passage representation against itself,即根据passage段落与当前passage word来提取信息。
$h_{t}^{P}=BiRNN(h_{t-1}^{P},[ v_{t}^{p},c_{t}])$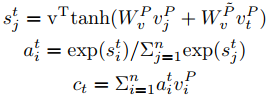
(4)output layer
利用pointer networks来predict the start and end position of the answer.
4.6 自注意力机制
R-NET中提到的概念是self-matching attention mechanism,近两年引起广泛关注的
Transformer模型也从自注意力这个思路出发。
什么是自注意力机制,Transformer模型文章里是这么说的:Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representations of the sequence.
循环网络的结构所需的序列化计算操作限制了计算的并行加速,卷积网络善于捕捉局部信息而对全局信息的建模稍弱。Google Brain等发表的文章[16]提出一个新的网络,只基于attention mechanisms,没有使用循环或卷积的结构,效果惊艳。
Tramsformer利用了多层叠加的self-attention及point-wise, fully connected layers构造编码层和解码层。![文献[16]](/images/machine_reading_attention/figure19.png)
Encoder:
输入层包括一个6层的stack结构。每一层包含两个子层。第一个是a multi-head self-attention mechanism,第二个是a simple, position-wise fully connected feed-forward network。经过layer normalization,接着应用a residual connection
LayerNorm(x+Sublayer(x)),然后输出一个512维的特征向量。
Decoder:
输出层也由6层的stack结构构成。在encoder中提到的两个子层的结构中,decoder在两层结构中插入一个子层,performs multi-head attention over the output of the encoder stack。employ residual connections around each of the sub-layers, followed by layer normalization。另外,通过masking使得预测时网络只会看到之前的信息。
对于Transformer来说,attention的设计是重点之一了。文中总结,一个注意力函数是对一个query 以及一个key-value对的集合建立映射函数。这里涉及query, keys, values三种模型中的向量,即Q、K、V。输出是values的带权加和,权重由query及对应的key计算得到。![文献[16]](/images/machine_reading_attention/figure20.png)
Scaled Dot-Product Attention
每个attention的计算公式如下:
$Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$
这里是用一个公式概括了注意力机制中权重的计算过程。 两种最常用的注意力权重计算方式是additive attention,即如第3部分中提到的,通过累加的方式;以及dot-product(multiplictive) attention, 即点乘的方式。在这里,Transformer用的是点乘的方式,不同的是乘上了一个缩放因子 $\frac{1}{\sqrt{d_{k}}}$。两种类型的attention计算理论复杂度差不多,而点乘的方式实现起来计算速度快,节省内存空间。文中提到,如果没有缩放,additive attention的效果比点乘的效果好。文中猜想这是因为点乘的结果值较大,影响softmax函数的结果,使得梯度值太小。
Multi-Head Attention
在进行注意力机制计算之前,需要先对Q、K、V向量进行线性变换。文章利用不同的线性变换向量,在不同的子空间对信息进行建模,这便是multi-head attention。
$MultiHead(Q,K,V)=Concat(head_{1},…,head_{h})W^{O}$
where $head_{i}=Attention(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V})$
其中$W_{i}^{Q} \in \mathbb{R}^{d_{model} \times d_{q}}$, $W_{i}^{K} \in \mathbb{R}^{d_{model} \times d_{k}}$, $W_{i}^{V} \in \mathbb{R}^{d_{model} \times d_{v}}$,$W^{O} \in \mathbb{R}^{hd_{v} \times d_{model}}$。文章设计了8个并行的注意力机制层,各层结果concate起来,即这里h=8。
模型中attention的应用:
上面说完了attention的计算方法,还要解决的一个问题是,Q,K,V分别是什么?
1) 在encoder-decoder attention层,Q来自于上一个decoder层,K和V来自于编码层的输出。解码的时候,每个时刻的解码过程模型可以“注意”到整个输入序列的信息。这种就是在sequence to sequence模型中典型的encoder-decoder 的注意力机制计算方法了。
2) 在编码器的self-attention,Q,K,V都来自于编码器中上一个编码层的输出。编码过程中每个时刻编码器都可以“注意”到上一个编码层的所有信息。
3) 在解码器的self-attention,Q,K,V都来自于解码器中上一个解码层的输出。含义与编码器的类似了。特别的,无效的未来时刻的信息会被mask掉。
参考文献:
[1] Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on Conference on information & knowledge management. ACM, 2013: 2333-2338.
[2] Bowman S R, Angeli G, Potts C, et al. A large annotated corpus for learning natural language inference[J]. arXiv preprint arXiv:1508.05326, 2015.
[3] Hermann K M, Kocisky T, Grefenstette E, et al. Teaching machines to read and comprehend[C]//Advances in Neural Information Processing Systems. 2015: 1693-1701.
[4] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[5] Graves A. Generating sequences with recurrent neural networks[J]. arXiv preprint arXiv:1308.0850, 2013.
[6] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[7] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems. 2017: 5998-6008.
[8] Cui Y, Chen Z, Wei S, et al. Attention-over-attention neural networks for reading comprehension[J]. arXiv preprint arXiv:1607.04423, 2016.
[9] Wang S, Jiang J. Learning natural language inference with LSTM[J]. arXiv preprint arXiv:1512.08849, 2015.
[10] Wang S, Jiang J. Machine comprehension using match-lstm and answer pointer[J]. arXiv preprint arXiv:1608.07905, 2016.
[11] Xiong C, Zhong V, Socher R. Dynamic coattention networks for question answering[J]. arXiv preprint arXiv:1611.01604, 2016.
[12] Hermann K M, Kocisky T, Grefenstette E, et al. Teaching machines to read and comprehend[C]//Advances in Neural Information Processing Systems. 2015: 1693-1701.
[13] Seo M, Kembhavi A, Farhadi A, et al. Bidirectional attention flow for machine comprehension[J]. arXiv preprint arXiv:1611.01603, 2016.
[14] Goodfellow I J, Warde-Farley D, Mirza M, et al. Maxout networks[J]. arXiv preprint arXiv:1302.4389, 2013.