一、问题描述
在中文分词领域有新词和未登录词的概念。新词,顾名思义即新出现的词语。未登录词,通常被定义为未在词典中出现的词。
在一般的分词业务场景中,无论词语是否为新词,其实我们需要找出的是未登录词。
本文的目的是先从一批语料中找出所有能成词的词语或词组;然后与已有分词工具(如hanLP)分词所得的结果进行对比,找出已有分词工具不能分出的词语,即未登录词。
这实际上是要“发现”特定语料中,所有能成词、或者说我们想分出的词语,包含新词、旧词、未登录词。为了叙述方便,本文不对这几个概念进行严格区分,简单地将其称为“新词发现”。
二、新词发现问题简介
新词发现不是一个很好解决的问题,它除了需要解决一般的分词方法所需解决的问题,还与语料的时效性密切相关。
比如说,在一般情况下,“英语老师”这个词语虽然具有独立的含义,但科目与老师的组合众多,如“语文老师”、“体育老师”等等,我们倾向于不把每一种老师都当作一个词语,而把“英语”、“语文”、“体育”、“老师”分别看作一个词语。但如果某一个时间段的语料中,“英语老师”有特殊的相关事件发生,“英语老师”出现的次数远远大于其他老师,则此时,我们倾向于把“英语老师”分作新词。类似情况的词组还有“周一见”、“超级月亮”等等。
新词发现方法一般分为基于规则的方法和基于统计的方法两大类。
基于规则的方法主要根据中文构词的规则(如基于构词的词性规则对候选词进行过滤),但这种方法需要人工建立规则,成本较高。
基于统计的方法则主要通过统计语料中的分布、频度信息等来判断字符串片段能否成词,如信息熵、邻接类别等等。
本文的新词发现实践,主要基于统计的方法,利用阈值设置,先从语料的字符串组合中筛选出一批候选词;然后利用逻辑回归方法训练一个成词与不成词的二分类模型,进一步确定新词。
三、新词发现算法实践
本文的新词发现算法主要包括:基于统计方法的候选词筛选 与 基于逻辑回归方法的词语筛选 两个部分。
1、基于统计方法的候选词筛选
首先考虑成词的两个重要标准:内部凝合程度和自由运用程度。
内部凝合程度即词语间各成分的不可分离程度。例如:“电影院”比“的电影”在各成分出现的条件下,会以更大的概率同时出现。为了算出一个文本片段的凝合程度,我们需要枚举它的凝合方式,即这个文本片段是由哪两部分组合而来。令 p(x) 为文本片段 x 在整个语料中出现的概率,以“电影院”为例,我们定义“电影院”的凝合程度为 p(电影院) 与 p(电) · p(影院) 比值和 p(电影院) 与 p(电影) · p(院) 的比值中的较小值。同理,“的电影”的凝合程度则是 p(的电影) 分别除以 p(的) · p(电影) 和 p(的电) · p(影) 所得的商的较小值。
可以想到,内部凝合程度较高的文本片段,诸如“蝙蝠”、“蜘蛛”、“彷徨”、“忐忑”、“玫瑰”之类的词,这些词里的每一个字几乎总是会和另一个字同时出现,而不在其他场合中使用。
自由运用程度较好理解,即其前后文的可灵活运用程度,可以用其左右邻字不同组合的种数来衡量。进一步,我们可以利用左右邻字的信息熵,来衡量一个文本片段的左邻字集合和右邻字集合有多随机。
文本片段的内部凝合程度和自由运用程度,两种判断标准缺一不可。只看凝合程度的话,程序会找出“巧克”、 “俄罗”、 “颜六色”、 “柴可夫”等实际上是“半个词”的片段;只看自由程度的话,程序则会把“吃了一顿”、 “看了一遍”、 “睡了一晚”、 “去了一趟”中的“了一”提取出来,因为它的左右邻字都太丰富了。
这里内部聚合度和自由运用度的详细介绍可以参考:
http://www.matrix67.com/blog/archives/5044
本文在这些概念的基础上,提取了字符串片段的词频、左邻字个数、右邻字个数、左邻字信息熵、右邻字信息熵、内部凝合程度 指标,并根据经验设定阈值,初步筛选出了一批候选词语。
其中,在统计这些指标的过程中利用了Nagao串频统计算法:
http://www.ar.media.kyoto-u.ac.jp/publications/Coling94.pdf
http://www.doc88.com/p-664123446503.html
一个符号串在文本中的出现次数,简称串频。这个方法主要用来高效统计我们设定的长度以内的字符串及其出现频次。
2、基于逻辑回归方法的词语筛选
实验发现,单凭人工设定的简单规则,较难去除一些不太适合成词的字符串,如“借我一”、“会担心”、“日子过得”等等。
对20161127这一天随机提取的20万语料通过上述统计的方法筛选出7040个字符串,人工标注后(成词标注为1,不成词标注为0,发现了772条负样本不太适合成词,占比10.96%。
于是,考虑通过逻辑回归方法,利用上述统计方法所得的特征,训练了一个成词与不成词的二分类模型。
进行了多次实验,包括对标注样本的探索、样本数量以及分类方法的不同尝试等等,最后选取1800条样本,其中负样本(不成词)772条全部选取,进行训练和测试。正样本随机选取,并随机取1000条样本作为训练集,800条作为测试集,实验结果波动不大,记录三次实验结果如下:
TPR表示ground truth成词的召回率。TNR表示groud truth为不成词,模型判断也为不成词的准确率。若在基于统计方法初筛出的候选词的基础上,把LR模型判断为不成词的字符串去掉,结合初筛的错误率10.96%,TPR按71%算,TNR按68%算,可以认为,整个新词发现方法得出的词语,错误率(不成词率)为10.96%(1-68%)/((1-10.96%)71%+10.96%*(1-68%))=5.26%,即准确率为94.74%。但由于词语难以枚举,且有些词语是否成词存在一定的模糊性,整个新词发现方法的召回率(即词语的查全率)不好评估。另外,新词发现方法的错误率和召回率相互制约。
把新词发现算法加入到热词提取中,热词提取的效果得到了提高,结果示例如下: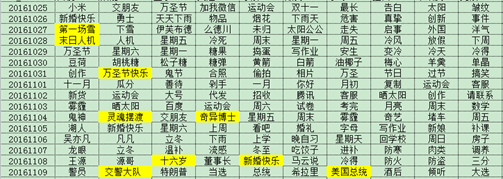
四、几点说明
1、通过基于统计的方法初筛出一批候选词后,利用LR模型可以进一步获取可以成词的字符串,这里包括新词、旧词、未登录词。
而另一方面,如果我们只想找出新出现的词,可以利用语料的时间序列,通过字符串在当前时间段的出现频数,与历史时间段的出现频数的比值,进一步筛选出新出现的词。
2、由于词语的统计指标,如词频、左邻字个数等,随语料规模有所变化,故阈值的设置应随语料规模有所调整。但对这个差异的要求并不严格,因为在语料规模达到一定程度时(若语料规模太小,也不构成能够发现新词的条件),它主要是影响了我们初筛的候选词的质量。
而统计特征的计算,与分类模型关系密切。特征值的标准不同,会影响到模型的参数。考虑模型的通用性,对新来的待训练语料,应先把统计特征映射到与模型的原训练语料一致的最大值最小值空间。
这样,对于新来的待训练语料,即可以使用已有的LR模型,降低新词发现的接入成本。