随着计算机网络技术的飞速发展,网络信息呈现爆炸式的增长。热词提取成为越来越普遍的问题。本文记录笔者在热词提取工作中的一些心得体会。
一、概述
热词反映了文本数据表现的人群在某个时间段普遍关注的问题和事物。
笔者热词提取的工作主要是根据一个时间段内的词频对比,再利用贝叶斯平均的思想,其中根据具体数据的情况做了些针对性的处理。
二、难点
笔者在做热词提取的过程中,发现或者遇到了以下一些问题,如:
1、热词提取是一个带有较大主观色彩的问题,热词提取的质量不好衡量。随人群、地域、个人主观看法都有所变化。
2、热词来源于文本,文本对热门话题表现的质量直接影响到热词提取的质量。有些文本的话题不能很好地表现一个大范围内的热点事件。
比如广告文本,某些广告会在一段时间内爆发性地发出,导致了某些词语的暴涨,而这些词语不能很好地体现热点话题
比如转发、评论、回复等的文本,这些内容的质量参差不齐,有些内容还是对突出热点话题或事件很有帮助的,而有些则不然。
有些文本里有较多重复的词语,有些文本的内容是重复的,这些重复是突出了热点话题或事件,还是突出了一些无关紧要的词语,这个也不容易智能地确定。
3、分词的问题。分词的准确性和新词的及时发现与热词提取的质量紧密相关。
4、图片、视频反映的热点如何得以结合?
5、如何提取更能反映话题或热点事件的词组?有时提取到的只是一个词语,但一个词语的暴涨不能体现热点话题或事件,如“歌声”不能体现“中国新歌声”这个节目。
6、语义挖掘问题。热词提取结果中难免会出现一些实际意义不大的词语,如“数字”、“筛选”等,它们可能是热点词组中的一部分,也有可能确实没有什么热门事件或话题的意义;又如“周五”、“星期一”这类有规律的周期性爆发的词语。
三、方法介绍
本文方法可以看作是tf-idf结合时间窗口,考虑贝叶斯平均思想的一个变种方法。具体介绍如下:
1、预处理
取当天和前两天的文本语料,对语料进行预处理,如去停词、中文常用字、过滤广告文本等。
2、词语的热度score计算
计算词语的热度可以考虑梯度,即计算词语当天出现的词频与前两天出现词频的差值。但这种方法存在一个问题,有些常用词语出现的频数很高,在波动上的绝对值也会较高;往往很容易就超越频数基数少的词语。如早安、雾霾等词语。
更合理的方法是利用当天的词频和历史词频的比值来衡量热度,这样可以排除那些每天的词频数都特别大的词语。
另一方面,这里还需排除一些频数特别小,而当天与历史词频比值非常高的词语。如词语W1和W2在统计当天分别出现了1000次和18次,历史两天分别出现了500次和3次,则直接计算词语当天与历史情况的词频比值的结果为2和6,但显然,其实词语W1更倾向于被判断为热词。这个问题可以通过贝叶斯平均的方法来解决。
贝叶斯平均方法可以用来衡量,或者说修正受欢迎程度问题的分数计算,其实际应用场景很广泛,如广告点击率的计算、用户投票的排名算法、热词提取等等。某种程度上,它可以理解为借鉴了“贝叶斯推断”的思想,即先对结果估计一个值,然后不断用新的信息去修正,使得它更接近客观答案。
具体计算方法如下:
计算词语当天出现的词频与整个统计时间段内的比值: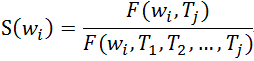
其中,$w_{i}$表示某个词语,$T_{j}$表示时间窗口,$F(w_{i},T_{j})$表示词语在时间窗口的出现频数。$S(w_{i})$表示某个词语目前的热度分数。
利用贝叶斯平均的方法修正热度分数,公式如下: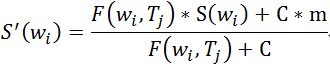
其中,m是一个先验的平均分,C是一个常数,与样本的总体情况有关。C越大,表示我们希望分数的总体分布差距越小。
在本文的热词提取问题中,m定义为所有词语的$S(w_{i})$的平均分,用$S_{average}$表示;C定义为所有词语的一天平均词频,用$F_{average}$表示,设I为词语总数,J为总天数,则: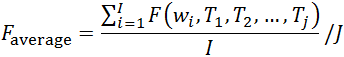
对上述贝叶斯平均公式进行变换,可得: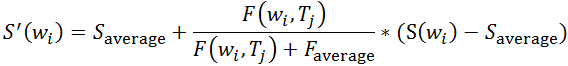
上述公式更容易理解,可以看作每个词语都有一个先验的平均分$S_{average}$,而其自身个性分数$(S(w_{i})-S_{average})$的权重,则由它表现得好不好来决定。它的词频较高,即曝光量大,我们就给予它的个性分数更大的权重。
不难发现,当词语的热度分数等于或小于当天的平均热度分数$S_{average}$,这个词语肯定不是热词,这里就不再考虑了。如果某个词语的词频特别小,远小于$F_{average}$,则其个性分数的词权重制约$\frac{F(w_{i},T_{j})}{F(w_{i},T_{j})+F_{average}}$将接近于0,这时即使其原分数特别高,修正后的分数也接近平均分。这样就筛掉了词频特别少,但数量变化比值大的词语。如果某个词语的词频特别大,词权重接近于1,但这种词往往是常用词,原分数会接近于平均分,则个性分数$(S(w_{i})-S_{average})$也会很小,热度分数也接近平均分,也被筛掉。
以三个词语的热度分数计算举例:
热度分数计算:
3、最后,就当然是根据词语的热度分数值筛选出热词了。
四、结果示例

五、总结
目前笔者所述的热词提取的方法能够取得一定的效果,把近日来的热点体现出来,但也还存在一些问题待解决。往后笔者会将新词发现的一些算法也结合进来。欢迎大家多批评,多提意见。