随着社交网络的发展和积累,内容的产生、传播、消费等已经根深蒂固地融入在人们的生活里。随之内容分析的工作也就走进了人们的视野。近年来,各种公众趋势分析类产品涌现,各大公司都利用自身资源纷纷抢占一席之地。
公众趋势分析平台利用自然语言处理、机器学习方法对数据进行分析,给用户提供舆情分析、竞品分析、数据营销、品牌形象建立等帮助。其中,热点发现问题是公众趋势分析中不可或缺的一部分。热点发现通过对海量数据(本文集中在文本数据方面)进行分析,挖掘相关人群重点关注的内容。
在很多业务场景中,快速高效地从海量社交短文本中发现出实时的热点话题,可以帮助产品、运营、公关等同学更好地吸引用户。然而,直接从海量文本中生成语法正确、意思明确的话题,是一件不容易的事情。本文主要介绍在话题生成上运用的一个较为简单高效的方法。
所谓话题
本文的目的是从海量社交短文本中,自动发现类似于新浪微博里,用户发起的话题,或者是运营同学后台配置的话题。
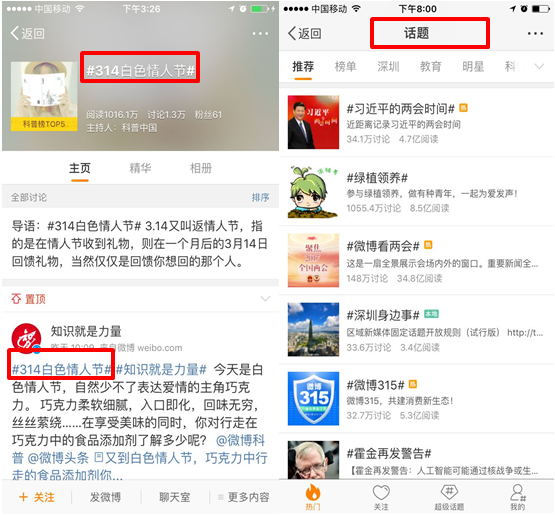
现有做法及对话题提取的想法
获取高质量的话题或事件,有非常多的需求或应用场景。但这不是一件容易的事,目前还没有一种成熟且鲁棒性强的方法可以解决这个问题。下面结合一些已有方法对话题提取的方法做一个简单的探讨。
直接截取新闻标题作为话题
但是这种做法有两个问题,1)有些新闻标题太长,且表达上话题属性偏弱;2)新闻事件不一定在所有平台都有关注热度,不适用于所有场景。
不少相关的工作,将话题提取当做主题分析来做,利用主题模型(LDA等)、聚类等方法来解决。
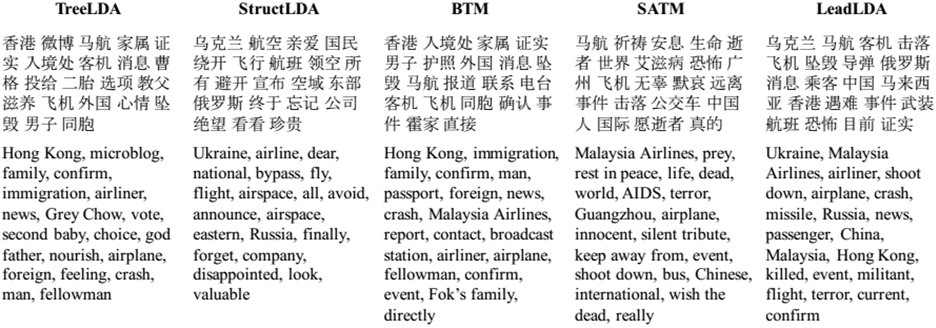
但这种做法的结果是找出各个话题的相关词,而不是直接生成话题。
可以考虑把话题发现当成summarization 问题来解决。
Summarization问题也有不同种类,从在线离线的角度可以分为直接从文本中获取Summarization,以及实时获取summarization。
Real-Time Web Scale Event Summarization,一般是先对信息流做一个决策,是否留下信息来作为一个事件,旨在检测出相关的、综合性强的、新颖的、实时性强的事件。
直接从文本中得到Summarization,也可以分为Multi-document summarization(MDS),以及Single document summarization,或者sentence summarization。放在这里的话题提取问题上,可以考虑用sentence summarization来解决。解决方法也分为Extractive models 以及Abstractive models两种,也就是直接提取式和生成式两种。提取式的效果会比生成式的效果保守一些,更具有实用性。现在比较新的有利用RNN和 Attention model来解决。但这种方法需要有监督的数据,算法的复杂度和鲁棒性有待进一步考察。之后可以尝试在这种方法上做一些适应性的改进。
本文的做法
本文提出一种从热词提取出发,提取热点话题的方法。下面是方法的整体流程图,首先提取热词,然后在热词的基础上,做话题提取。下面分两部分详细介绍。
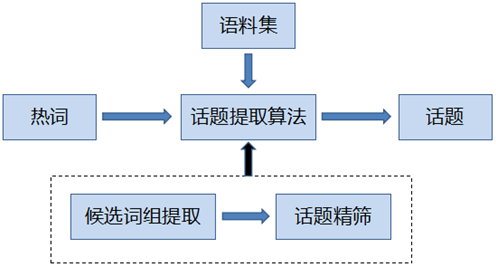
热词提取
主体思路是利用词频梯度和平滑方法。
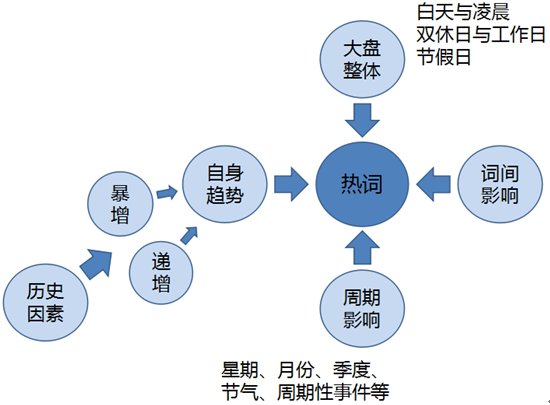
如上图所示,词语的热度受很多方面的影响。
- 大盘影响:白天和凌晨、双休日和工作日、节假日和平常日子,社交消息的整体数量都会有一个较大的波动。
- 词间影响:也许语料中某个段子突然非常火,会导致一些一般情况下关系不大的词语,一下子全部成为热词。
- 周期影响:24小时、星期、月份、节气等周期性的变化,常常会使得“早安”、“周一”、“三月”等事件意义性不强的词语成为热词。最近很火的“歌手”周播节目,也使得“歌手”周期性地成为热词,不过这种热词对我们来说,是更有意义的。
- 自身趋势:这个就是我们最关心的热度信息了。这些由于事件引起的相关词语突发性、递增性等的增长,就是我们算法想要识别和分析出来的。
针对以上一些影响因素,可以从以下的一些方面进行热词提取工作。
1、预处理
这里主要包括文本去重、微商识别等方法,对数据进行一些去躁的工作。
2、梯度
词频增量的主要衡量指标。
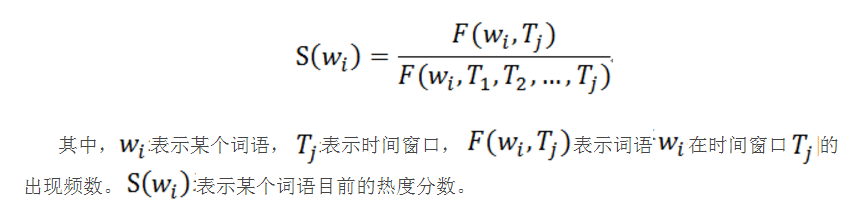
其中,$$w_i$$表示某个词语,$$T_j$$表示时间窗口,$$F(w_i,T_j)$$表示词语$$w_i$$在时间窗口$$T_j$$的出现频数。$$S(w_i )$$表示某个词语的梯度分数。
3、贝叶斯平均
一种利用outside information,especially a pre-existing belief,来评价the mean of a population的方法。
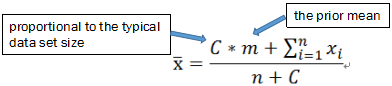
贝叶斯平均的典型应用包括用户投票排名,产品评分排序,广告点击率的平滑等等。
以用户投票排名为例,用户投票评分的人很少,则算平均分很可能会出现不够客观的情况。这时引入外部信息,假设还有一部分人(C人)投了票,并且都给了平均分(m分)。把这些人的评分加入到已有用户的评分中,再进行求平均,可以对平均分进行修正,以在某种程度或角度上增加最终分数的客观性。容易得到,当投票人数少的时候,分数会趋向于平均分;投票人数越多,贝叶斯平均的结果就越接近真实投票的算术平均,加入的参数对最终排名的影响就越小。
4、热度分数计算
利用贝叶斯平均对梯度分数进行修正。

这里,公式中的平均词频是贝叶斯平均公式中的C,平均分是贝叶斯平均公式中的m。也就是说在热词提取中,用梯度分数的平均分作为先验m,用平均词频作为C。
热词提取中可以这么理解,词语每出现一次,相当于给词的热度进行了评分。
词频少,也就代表了评分的人数少,则评分的不确定性大,需要用平均分来进行修正、平滑。这里可以把一些词频很少的词语的高分数拉下来,例如一个词语今天出现了18次,昨天出现了6次,这里梯度分数就比较高,为0.75,但这种词语其实更可能不是一个热词。
词频大,远大于平均词频的词语,也就代表了评分的人数多。则分数会越趋向于自己的实际分数,这时平均分的影响变小。这是合理的,例如一个本来是百万量级的词语,第二天也出现了一个三倍的增量,这里热度价值就明显提高了。
5、差分
这里主要考虑是要解决热词的周期性影响的问题。具体做法非常简单,比较的时间间隔需包含一些影响较为明显的时间周期。例如按小时统计的热词,最好是拿今天和昨天一个相同的时间点进行比较。
6、共现模型
对于互为共现词的热词,进行一层筛选。
但这些词语通过一些频繁项集、word2vector等方法,都可以发现出共现的关系。利用共现词语的信息,可以对热词进行一轮筛选,提取出最有价值的热词,避免信息冗余。
7、时间序列分析
考虑更详细的历史因素。
通过对词频进行时间序列分析,可以更详细地区分短期、长期与周期性热点;对一些更有价值的热词做热度预警;对热词的增长趋势进行分析等等。
综上,我们在周期时间间隔内,通过贝叶斯平均修正的词语梯度分数来分析词语热度,并利用语料中词语的共现信息,进一步筛选得出热词。通过时间序列分析,得出热词的特性和增长趋势等。
话题提取
提取出了热词,但一个词语对于事件或者话题的表达能力是有限的。这里从热词出发,进一步提取出话题。
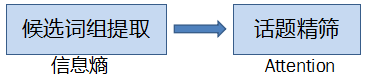
话题提取的工作也分为两步,第一步先找出一些候选的话题词组;第二步利用Attention的思想,从候选词组中找出一个包含的词语更加重要的词组,作为输出话题。
候选词组提取
候选词组的提取主要根据信息熵的理论,用到以下一些特征。
1、内部聚合度——互信息
这应该从信息熵说起。信息熵是用来衡量一个随机变量出现的期望值,一个变量的信息
熵越大,表示其可能出现的状态越多,越不确定,也即信息量越大。
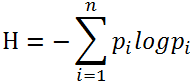
互信息可以说明两个随机变量之间的关系强弱。定义如下:
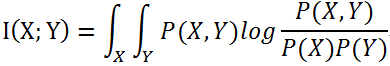
对上式做变换可以得到:
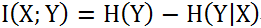
H(Y)表示Y的不确定度;H(Y│X)表示在已知X的情况下,Y的不确定度,也即已知X时,Y的条件熵。则可知I(X;Y)表示由X的引入而使Y的不确定度减小的量。I(X;Y)越大,说明X出现后,Y出现的不确定度减小,即Y很可能也会出现,也就是说X、Y关系越密切。反之亦然。
2、所处语境的丰富程度——左右信息熵
刚刚已经提到信息熵说明了信息量的大小。那么如果一个词组的左右信息熵越大,即词
组左右的可能情况越多,左右的搭配越丰富;则说明这个词组在不同的语境里可讨论的事情越多,越可能可以独立说明一个事件或话题。
3、是否普遍——这个很直观地可以通过词组出现的频次来衡量。
话题精筛
对于某一个热词,挑选出来一批候选词组后,每个词组所含的词语不同,包含的信息量也不同。比如3月9日对于“巴黎”这个热词,我们提取出来的候选词组有“巴黎球迷”、“巴黎球员”、“淘汰巴黎”、“心疼巴黎”、“巴萨逆转巴黎”、“法国巴黎”、“巴黎时装周”。但“巴萨球员”、“巴黎球迷”、“淘汰巴黎”、“心疼巴黎”、“法国巴黎”这些词组中,“球员”、“球迷”、“淘汰”、“心疼”这些词语在很多其他的语境中也经常出现,它们的指向性并不明确;“法国巴黎”的信息量甚至只有一个地点。而“巴萨逆转巴黎””、 “巴黎时装周”则还包含了更具体的信息——足球比赛、球队、赛果或者时装秀等,事件的指向更明确。这里,就需要对候选的话题词组进行筛选。

筛选的主要依据或思想,其实和Attention机制是一样的,关键是要找出重要的词语。比如与“巴黎”的搭配,“巴萨”、“逆转”、“时装周”比“球迷”、“球员”、“心疼”、“法国”包含的信息更多,意义更大。可以想到,“巴萨”、“逆转”、“时装周”这些词语在其他无关语料中不常出现,“球迷”、“球员”、“心疼”、“法国”在不同语料中都常会出现,信息不明确。所以,在这个问题中,可以通过TF-IDF的思路来确定哪些词语更重要,有更高的“attention”权重。
具体说来,就是衡量词组中,各个词语在词组中的特异性。我们有理由相信,“巴萨”、“逆转”、“时装周”这些词语,在含“巴黎”的相关语料中出现的概率较高。热词$$w^h$$的候选词组s的事件或话题表示能力分数可由以下公式求得:
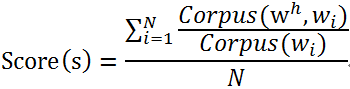
其中,N为候选词组中的词语个数,$$w_i$$为候选词组中包含的第i个词语,Corpus (w)表示含有词语w的相关语料。
另一方面,也需要考虑词组出现的频次,词组出现的次数越多,说明事件越重要。
综上所述,通过候选词组的事件或话题表示能力分数以及出现频次,精筛出热词的相关话题。