1.从问答系统说起
1950年,阿兰·图灵发表了一篇划时代的论文,提出了著名的图灵测试:如果一台机器能够与人类展开对话(通过电传设备)而不能被辨别出其机器身份,那么称这台机器具有智能。问答系统有了最早的实现构想。
在60到70年代已经有了计算机自动问答的系统。例如能回答棒球比赛相关问题的自动问答系统BASEBALL,回答阿波罗登月取回的岩石样本分析结果相关问题的LUNAR。这个时期的问答系统主要是面向限定领域、处理结构化数据的,被称为人工智能时期,主要是人工智能系统或专家系统。70和80年代,随着计算语言学的兴起,问答系统也进入计算语言时期,计算语言学帮助降低数据库构建的成本,降低问答系统的构建难度。这个时期的问答系统集成了自然语言处理、知识表示等方法分析用户问题给出答案。进入90年代,问答系统则进入了开放领域、自由文本时期,结合机器学习、信息检索等方法。
从发展历史看来,问答系统的发展历程可以简单概括为:基于结构化数据的问答系统、基于自由文本的问答系统、基于问题答案对的问答系统三个阶段。
早期由于智能技术及数据获取的局限性,问答系统主要是面向限定领域,该时期的问答系统处理的数据类型是简单且高度结构化的数据,系统一般将输入问题转化为数据库查询语句,通过数据库的检索返回答案。基于结构化数据的问答系统包含上文提到的人工智能时期和计算语言时期。
问答系统对知识数据的组织形式要求越严格,说明需要的“人工”越多,那么系统的“智能”程度就越低。随着互联网的飞速发展以及信息检索技术的兴起,90年代问答系统进入面向开放领域,基于自由文本数据的发展时期。这种问答系统的处理流程主要包括:问题分析、文档检索及段落划分、候选答案抽取、答案排序、答案验证等。特别自1999年文本检索会议(Text Retrieval Conference,简称TREC)引入问答系统评测专项(Question Answering Track,简称QA Track)以来,极大推动了基于自然语言处理技术在问答领域中的研究发展。
基于问题答案对的问答系统主要涉及CQA(community question answering)与FAQ(Frequently asked questions)两种类型。网络上出现的社区问答(community question answering, CQA)提供了大规模的用户交互衍生的问题答案对(question-answer pair, QA pair)数据,为基于问答对的问答系统提供了稳定可靠的问答数据来源。与CQA相比,FAQ具有限定领域、质量高、组织好等优点,使得系统回答问题的水平大大提高。但FAQ的获取成本高,这个缺点又制约了基于FAQ的问答系统的应用范围。
随着计算机、大数据、人工智能、自然语言处理等相关技术的发展,人们对问答系统的期待越来越高。巧妇难为无米之炊,问答系统接收的知识数据越多,才可能越聪明。近年来,可收集的数据呈爆发式增长,在学术界和工业界,针对不同的场景或者说不同的数据形态,衍生出不同种类的问答系统,如FAQ检索型、闲聊型、任务型、知识图谱型(KBQA)以及文档型(阅读理解)等。这些不同类型的问答系统,按照交互轮次,可以分为多轮和单轮会话;按照解决方法,可以分为基于检索的、基于生成的以及基于知识库的问答。
FAQ检索型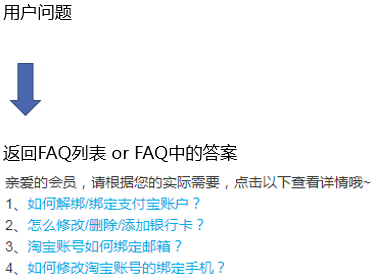
知识图谱型(KBQA)
任务型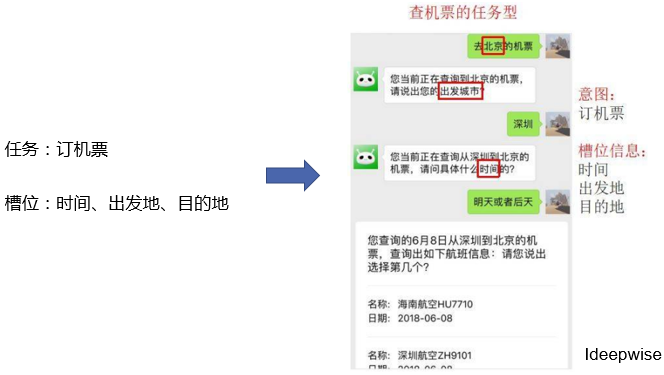
在上面提到的各种问答系统中,旨在“负责任”地准确解决用户问题有FAQ检索型、任务型、知识图谱型以及文档型。显然,除了文档型机器人,其他类型的对话机器人都需要不同程度的数据组织,来辅助计算机理解和回答用户问题。其中,FAQ检索型需要整理问题答案对,知识图谱型需要整理知识关系网络,任务型需要任务场景和槽位的定制。从算法角度来看,知识的质量、结构化程度越高,问答系统的效果才越好,才越“智能”。但对知识的组织程度要求越高,就需要越多的“人工”,应用落地的成本则越大。这同时也会影响系统能够解决问题的覆盖度。从这个角度看来,文档型问答的优势便在于无需结构化知识的预先整理,接入成本低。所以在飞速发展的文本理解技术中得到了越来越多的关注。
文档型